层级
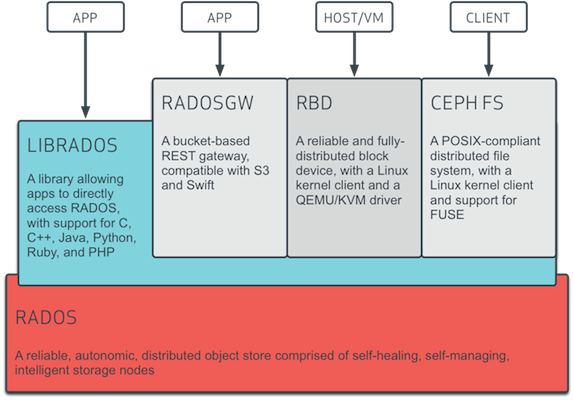
RADOS 分布式存储相较于传统分布式存储的优势在于:
- 将文件映射到object后,利用Cluster Map 通过CRUSH 计算而不是查找表方式定位文件数据存储到存储设备的具体位置。优化了传统文件到块的映射和Block MAp的管理。
- RADOS充分利用OSD的智能特点,将部分任务授权给OSD,最大程度地实现可扩展。
对象寻址过程
PGID=POOL_ID+HASH(OBJ_ID)%PG_NUM对象的id 通过hash映射,然后用PG总数对hash值取模得到pg idCRUSH(PGID) => OSD通过crush算法计算PG 上的对象分布到哪些OSD硬盘上
CRUSH算法的希望达成的目标:
- 数据均匀的分布到集群中;
- 需要考虑各个OSD权重的不同(根据读写性能的差异,磁盘的容量的大小差异等设置不同的权重);
- 当有OSD损坏需要数据迁移时,数据的迁移量尽可能的少;
CRUSH 算法
CRUSH_HASH(PGID,OSDID,R) = DRAW输入PG id、可供选择的OSD id 列表,和一个常量,通过一个伪随机算法,得到一个随机数,伪随机算法保证了同一个key总是得到相同的随机数,从而保证每次计算的存储位置不会改变(DRAW &0xffff) * OSD_WEIGHT = OSD_STRAW将上面得到的随机数和每个OSD的权重相乘,然后挑出乘积最大的那个OSD
样本容量足够大后,随机数对挑中结果不影响,OSD权重起决定作用,权重越大,挑中概率越大。 通过随机算法让数据均衡分布,乘以权重让挑选的结果考虑了权重;而如果出现故障OSD,只需要恢复这个OSD上的数据,不在这个节点上的数据不需移动
一个Pool里设置的PG数量是预先设置的,PG的数量不是随意设置,需要根据OSD的个数及副本策略来确定, 线上尽量不要更改PG的数量,PG的数量的变更将导致整个集群动起来(各个OSD之间copy数据),大量数据均衡期间读写性能下降严重。 预先规划Pool的规模,设置PG数量;一旦设置之后就不再变更;后续需要扩容就以 Pool 为维度为扩容,通过新增Pool来实现(Pool通过 crushmap实现故障域隔离)
原因:PG是寻址第一步中的取模参数,变更PG会导致对象的PG id 都发生变化,从而导致整个集群的数据迁移
cluster map更新
cluster map信息是以异步且lazy的形式扩散的。monitor并不会在每一次cluster map版本更新后都将新版本广播至全体OSD, 而是在有OSD向自己上报信息时,将更新回复给对方。类似的,各个OSD也是在和其他OSD通信时, 如果发现对方的osd中持有的cluster map版本较低,则把自己更新的版本发送给对方。
CEPH 设置管理网段,OSD节点同步网段,客户网段,这样可以分担网口IO压力,减小在数据清洗时,客户端读写性能下降影响